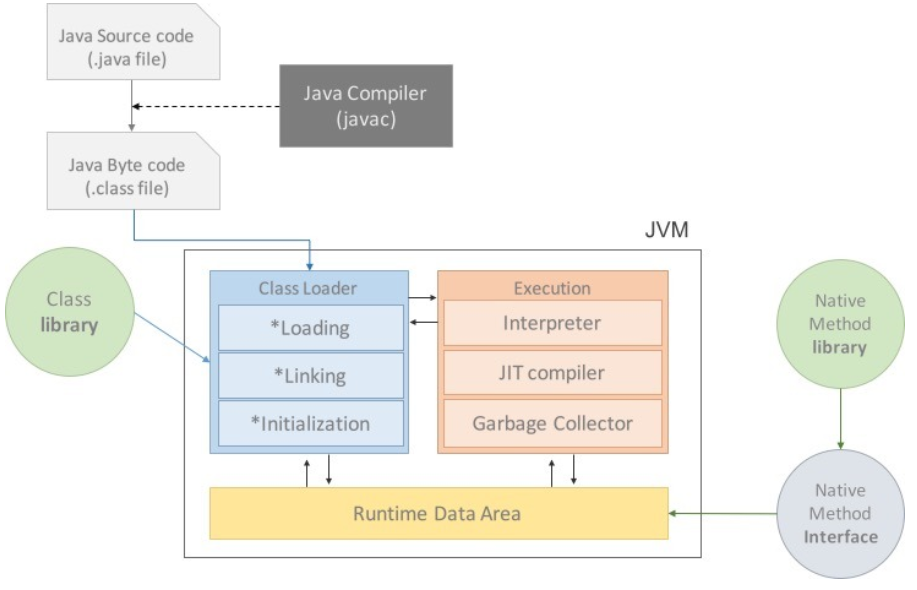
자바 컴파일 과정 이미지 출처:https://kunhee.kim/programming/basic-java-0/
기존의 C/C++의 프로그래밍 언어는 컴파일 플랫폼과 타겟 플랫폼이 다를 경우 프로그램이 동작하지 않았다.
예를들어 Mac에서 컴파일하고 Mac에서 프로그램을 실행을 하면 돌아가지만 windows에서 실행하면 실행이 되지 않는...
자바는 OS에 종속적이지 않다. 이 OS에 종속받지 않고 실행하기 위해 OS 위에서 JVM이 필요하다.
JVM이 있으므로 인해서 OS별로 컴파일을 할 필요가 없지만 운영체제에 맞는 JVM이 설치가 되어 있어야 한다.
컴파일 과정
Java 소스코드: 우리가 인텔리제이나 이클립스등에서 작성하는 코드들 확장자가 (클래스이름.java)로 되어 있다.
이 소스코드는 CPU가 인식을 하지 못하므로 기계어로 컴파일을 해줘야 한다.
컴파일러 : JDK 폴더 - bin - javac.exe 가 우리가 작성한 소스코드를 컴퓨터가 이해할 수 있는 바이트코드로 바꿔준다.
Java 클래스 파일(바이트코드) : 컴파일이 된 소스코드는 (클래스이름.class)로 클래스 파일이 생성이 되게 된다.
Java 소스코드 이미지자바 컴파일 명령어 javac
터미널에서 소스코드가 있는 경로로 이동한 후에 javac Hello.java 를 입력후 Enter를 누르면
컴파일 후 클래스 파일 생성
다시 해당 경로를 ls 명령어를 통해 확인 해보면 이전에는 없던 Hello.class가 생성이 된 걸 볼 수 있다.
터미널에 java Hello를 입력하면 "Hello!!"가 출력이 된다.
바이트 코드
가상 컴퓨터에서 돌아가는 실행 프로그램을 위한 이진 표현법
자바 바이트 코드는 JVM이 이해할 수 있는 언어로 변환된 자바 소스코드를 의미 컴파일러에 의해 변환된 코드 명령어 크기가 1바이트 여서 자바 바이트 코드라고 불린다.
바이트 코드는 실시간 번역기나 JIT 컴파일러에 의해 바이너리 코드로 변환이 된다.
💡 바이너리 코드란? 바이너리 코드 또는 이진 코드라고 함 컴퓨터가 인식할 수 있는 0과 1로 구성된 이진코드
💡 기계어란?
0과 1로 이루어진 바이너리 코드이다.기계어가 이진코드로 이루어졌을 뿐 모든 이진코드가 기계어인 것은 아니다.기계어는 특정한 언어가 아니라 CPU가 이해하는 명령어 집합이며, CPU 제조사마다 기계어가 다를 수 있다.
JIT 컴파일러(Just-in-time compliation)
JIT 컴파일러는 프로그램을 실제 실행하는 시점에 기계어로 번역하는 컴파일러다.
Java 소스 코드에서 컴파일된 바이트 코드는 기계가 바로 읽을 수 있는 형태가 아니기 때문에 실행 될 때 기계가 읽을 수 있는 Native Code로 컴파일을 하게 되는데 JIT Compiler가 이 역할을 하게 된다. JIT 컴파일링은 실행될 때 최초 실행되기 때문에, 최초 실행에서는 조금 느릴 수 있다.
JVM 구성요소
JVM 구성 요소
JVM 구성 요소는 크게 아래와 같이 이루어져 있다.
클래스 로더(Class Loader)
런타임 데이터 영역(Runtime Data Area)
실행 엔진(Execution Engine)
인터프리터
JIT 컴파일러
가비지 콜렉터
클래스 로더(Class Loader)
바이트 코드들을 불러와서 자바의 런타임 데이터 영역(자바의 메모리)에 넣는다. 런 타임시 동적으로 클래스를 로드하고 jar 파일 내 저장된 클래스들을 런타임 데이터 영역에 넣는다. 클래스를 처음으로 참조할 때, 해당 클래스를 로드하고 링크하는 역할
실행 엔진(Execution Engine)
클래스를 실행 시키는 역할 클래스 로더가 JVM 내의 런타임 데이터 영역에 바이트 코드를 배치되고, 실행 엔진에 의해 실행이 된다. 바이트 코드는 기계가 실행할 수 있는 형태가 아니기 때문에 JVM 내부에서 기계가 실행할 수 있는 형태로 변환한다.
인터프리터 - 실행 엔진은 바이트 코드를 명령어 단위로 읽어서 실행, 한 줄씩 수행하기 때문에 느리다.
JIT 컴파일러(Just-In-Time) - 인터프리터 방식으로 실행하다 적절한 시점에 바이트 코드 전체를 컴파일하여 기계어로 변경 - 이후에는 더 이상 인터프리팅 하지 않고 기계어로 직접 실행하는 방식
가비지 콜렉터 - 사용되지 않는 인스턴스를 찾아 메모리에서 해제 시킨다.
런타임 데이터 영역(Runtime Data Area)
프로그램을 수행하기 위해 OS에서 할당 받은 메모리 공간
Runtime Data Area
PC Register - 쓰레드 실행 시에 생성, 쓰레드마다 하나씩 존재 - 쓰레드가 어떤 어떤 부분을 어떤 명령으로 실행해야할 지에 대한 기록을 하는 부분 - 현재 수행중인 JVM 명령 주소를 갖는다.
💡프로세스(process)란? 단순히 실행 중인 프로그램(program)
즉, 사용자가 작성한 프로그램이 운영체제에 의해 메모리 공간을 할당받아 실행 중인 것을 말한다.
이러한 프로세스는 프로그램에 사용되는데이터와 메모리 등의 자원 그리고 스레드로 구성된다.
💡 스레드(thread)란?
스레드(thread)란 프로세스(process) 내에서 실제로 작업을 수행하는 주체를 의미
모든 프로세스에는 한 개 이상의 스레드가 존재하여 작업을 수행한다.
또한, 두 개 이상의 스레드를 가지는 프로세스를 멀티스레드 프로세스(multi-threaded process)라고 한다.
✔ JVM Stack
프로그램 실행과정에서 임시로 할당되었다가 메소드를 빠져나가면 바로 소멸되는 특성의 데이터를 저장하기 위한 영역이다. 각종 형태의 변수나 임시 데이터, 스레드나 메소드의 정보를 저장한다. 메소드 호출 시마다 각각의 스택 프레임(그 메서드만을 위한 공간)이 생성된다. 메서드 수행이 끝나면 프레임 별로 삭제를 한다. 메소드 안에서 사용되는 값들을 저장한다. 또 호출된 메소드의 매개변수, 지역변수, 리턴 값 및 연산 시 일어나는 값들을 임시로 저장한다.
✔ Native method stack
자바 프로그램이 컴파일되어 생성되는 바이트 코드가 아닌 실제 실행할 수 있는 기계어로 작성된 프로그램을 실행시키는 영역. JAVA가 아닌 다른 언어로 작성된 코드를 위한 공간. Java Native Interface를 통해 바이트 코드로 전환하여 저장하게 된다. 일반 프로그램처럼 커널이 스택을 잡아 독자적으로 프로그램을 실행시키는 영역
✔ Method Area (= Class Area = Static area)
클래스 정보를 처음 메모리 공간에 올릴 때 초기화되는 대상을 저장하기 위한 메모리 공간
✔ Runtime Constant Pool
스태틱 영역에 존재하는 별도의 관리영역. 상수 자료형을 저장하여 참조하고 중복을 막는 역할을 수행한다.
💡 스태틱 영역에 저장되는 데이터
Field Information (멤버 변수!) 멤버변수의 이름, 데이터 타입, 접근 제어자에 대한 정보
Method Information (메소드!) 메소드의 이름, 리턴타입, 매개변수, 접근 제어자에 대한 정보
Type Information (타입!) class인지 interface인지의 여부 저장. Type의 속성, 전체 이름, super 클래스의 전체 이름. (interface이거나 object인 경우 제외된다. 이건 Heap에서 관리함)
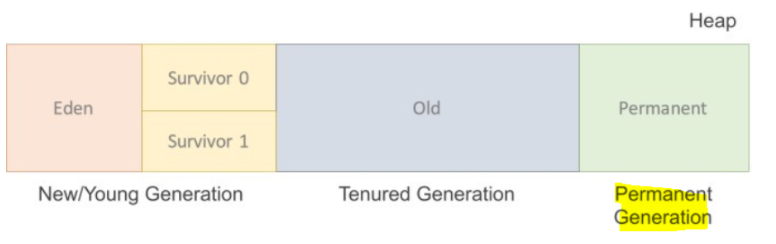
✔Heap 영역
Heap 영역
✔Permanent Generation
직역하면 영구적인 세대이다. 생성된 객체들의 정보의 주소값이 저장된 공간이다. 클래스 로더에 의해 load되는 Class, Method 등에 대한 Meta 정보가 저장되는 영역이고 JVM에 의해 사용된다.Reflection을 사용하여 동적으로 클래스가 로딩되는 경우에 사용된다.
💡 Reflection이란? 객체를 통해 클래스의 정보를 분석해 내는 프로그래밍 기법 구체적인 클래스 타입을 알지 못해도, 컴파일된 바이트 코드를 통해 역으로 클래스의 정보를 알아내어 사용할 수 있다는 뜻이다.
✔New/Young 영역
이곳의 인스턴스들은 추후 가비지 콜렉터에 의해 사라진다. 생명 주기가 짧은 “젊은 객체”를 GC 대상으로 하는 영역이다. 여기서 일어나는 가비지 콜렉트를 Minor GC라고 한다.
Eden: 객체들이 최초로 생성되는 공간 Survivor 0, 1: Eden에서 참조되는 객체들이 저장되는 공간
Eden 영역에 객체가 가득차게되면 첫번째 가비지 콜렉트가 발생한다. Eden 영역에 있는 값 들을 Survivor 1 영역에 복사하고 이 영역을 제외한 나머지 객체를 삭제한다.
✔Old 영역
이곳의 인스턴스들은 추후 가비지 콜렉터에 의해 사라진다.생명 주기가 긴 “오래된 객체”를 GC 대상으로 하는 영역이다.여기서 일어나는 가비지 콜렉트를 Major GC 라고 한다. Minor GC에 비해 속도가 느리다. New/Young Area에서 일정시간 참조되고 있는, 살아남은 객체들이 저장되는 공간이다.
애플리케이션의 비즈니스 로직이 올바르게 동작하려면 데이터를 사전 검증하는 작업이 필요하다. 이것을 유효성 검사 또는 데이터 검증이라고 부른다.
유효성 검사(validation)은 프로그래밍에서 매우 중요한 부분이며, 자바에서 가장 신경 써야 하는 것 중 하나로 NullPointException 예외가 있다.
일반적인 애플리케이션 유효성 검사의 문제점
계층별로 진행하는 유효성 검사는 검증 로직이 각 클래스별로 분산돼 있어 관리가 어렵다.
검증 로직에 의외로 중복이 많아 여러 곳에 유사한 기능의 코드가 존재할 수 있다.
검증해야 할 값이 많다면 검증하는 코드가 길어진다.
이러한 문제로 코드가 복잡해지고 가독성이 떨어진다.
위의 문제를 해결하기 위해 자바 진영에서는 2009년부터 Bean Validation이라는 데이터 유효성 검사 프레임워크를 제공 Bean Validation은 어노테이션을 통해 다양한 데이터를 검증하는 기능을 제공 Bean Validation을 사용한다는 것은 유효성 검사를 위한 로직을 DTO 같은 도메인 모델과 묶어서 각 계층에서 사용하면서 검증 자체를 도메인 모델에 얹는 방식으로 수행한다는 의미 어노테이션을 사용한 검증 방식이기 때문에 코드의 간결함 유지 가능
Hibernate Validator
Bean Validation 명세의 구현체
스프링 부트에서는 Hibernate Validator를 유효성 검사 표준으로 채택해서 사용
애플리케이션을 개발할 때는 불파기하게 많은 오류가 발생하게 된다. 자바에서는 이러한 오류를 try-catch, throw 구문을 활용해 처리 스프링 부트에서는 더욱 편리하게 예외를 처리할 수 있는 기능을 제공 스프링 부트에서 적용할 수 있는 예외 처리 방식에 대해 학습
예외와 에러
예외(exception) : 입력 값의 처리가 불가능하거나 참조된 값이 잘못된 경우 등 애플리케이션이 정상적으로 동작하지 못하는 상황을 의미, 예외는 개발자가 직접처리할 수 있는 것이므로 미리 코드 설계를 통해 처리 가능
에러(error) : 에러는 주로 자바의 가상머신에서 발생시키는 것으로 예외와 달리 애플리케이션에서 코드로 처리할 수 있는 것이 거의 없다. 대표적인 예로 메모리부족(OutOfMemory), 스택 오버플로(StackOverFlow)등이 있다. 에러는 발생 시점에 처리하는 것이 아닌 미리 애플리케이션의 코드를 살펴보면서 문제가 발생하지 않도록 예방해서 원천적으로 차단해야 한다.
예외 클래스
Checked Exception과 UnChecked Exception
Checked Exception : 컴파일 단계에서 확인 가능한 예외 상황, 이러한 예외는 IDE에서 캐치해서 반드시 예외 처리를 할 수 있게 표시 해준다.
Uncheck Exception : 런타임 단계에서 확인되는 예외 상황, 문법상 문제는 없지만 프로그램 동작 중 예기치 않은 상황이 생겨 발생하는 예
간단히 분류하자면 RuntimeException을 상속받은 Exception 클래스는 Unchecked Exception이고 그렇지 않은 Exception 클래스는 Checked Exception
예외 처리 방법
예외가 발생 시 처리하는 방법은 크게 3가지가 있다.
예외 복구
예외 상황을 파악해서 문제를 해결하는 방식 대표적인 방법이 try-catch
예외 처리 회피
예외가 발생한 시점에서 바로 처리하는 것이 아닌 예외가 발생한 메서드를 호출한 곳에서 에러 처리를 할 수 있게 전가하는 방식, 이때 throw 키워드를 사용해 어떤 예외가 발생했는지 호출부에 내용을 전달할 수 있다.
예외 전환
앞의 두 방식을 적절하게 섞은 방식, 예외가 발생 시 어떤 예외가 발생했느냐에 따라 호출부로 예외 내용을 전달하면서 좀 더 적합한 예외 타입으로 전달할 필요가 있다. 또는 애플리케이션에서 예외 처리를 좀 더 단순하게 하기 위해 래핑(wrapping)해야 하는 경우도 있다. 이런 경우 try-catch방식을 사용하면서 catch 블록에서 throw 키워드를 사용해 다른 예외 타입으로 전달하면 된다.
스프링 부트의 예외 처리 식
@(Rest)ControllerAdvice와 @ExceptionHandler를 통해 모든 컨트롤러의 예외를 처리
@ExceptionHandler를 통해 특정 컨트롤러의 예외를 처리
@ControllerAdvice 대신 @RestControllerAdvice를 사용하면 결괏값을 JSON 형태로 반환할 수 있다.
import java.util.HashMap;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
@RestControllerAdvice //(basePackages = "com.springboot.valid_exception")
public class CustomExceptionHandler {
private final Logger LOGGER = LoggerFactory.getLogger(CustomExceptionHandler.class);
@ExceptionHandler(value = RuntimeException.class)
public ResponseEntity<Map<String, String>> handleException(RuntimeException e,
HttpServletRequest request) {
HttpHeaders responseHeaders = new HttpHeaders();
HttpStatus httpStatus = HttpStatus.BAD_REQUEST;
LOGGER.error("Advice 내 exceptionHandler 호출, {}, {}", request.getRequestURI(),
e.getMessage());
Map<String, String> map = new HashMap<>();
map.put("error type", httpStatus.getReasonPhrase());
map.put("code", "400");
map.put("message", e.getMessage());
return new ResponseEntity<>(map, responseHeaders, httpStatus);
}
@ExceptionHandler(value = MethodArgumentNotValidException.class)
public ResponseEntity<Map<String, String>> handleException(MethodArgumentNotValidException e,
HttpServletRequest request) {
HttpHeaders responseHeaders = new HttpHeaders();
HttpStatus httpStatus = HttpStatus.BAD_REQUEST;
Map<String, String> map = new HashMap<>();
map.put("error type", httpStatus.getReasonPhrase());
map.put("code", "400");
map.put("message", e.getMessage());
return new ResponseEntity<>(map, responseHeaders, httpStatus);
}
@ExceptionHandler(value = CustomException.class)
public ResponseEntity<Map<String, String>> handleException(CustomException e,
HttpServletRequest request) {
HttpHeaders responseHeaders = new HttpHeaders();
LOGGER.error("Advice 내 handleException 호출, {}, {}", request.getRequestURI(),
e.getMessage());
Map<String, String> map = new HashMap<>();
map.put("error type", e.getHttpStatusType());
map.put("code", Integer.toString(e.getHttpStatusCode()));
map.put("message", e.getMessage());
return new ResponseEntity<>(map, responseHeaders, e.getHttpStatus());
}
}
import com.springboot.valid_exception.common.Constants.ExceptionClass;
import com.springboot.valid_exception.common.exception.CustomException;
import java.util.HashMap;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/exception")
public class ExceptionController {
private final Logger LOGGER = LoggerFactory.getLogger(ExceptionController.class);
@GetMapping
public void getRuntimeException() {
throw new RuntimeException("getRuntimeException 메소드 호출");
}
@ExceptionHandler(value = RuntimeException.class)
public ResponseEntity<Map<String, String>> handleException(RuntimeException e,
HttpServletRequest request) {
HttpHeaders responseHeaders = new HttpHeaders();
responseHeaders.setContentType(MediaType.APPLICATION_JSON);
HttpStatus httpStatus = HttpStatus.BAD_REQUEST;
LOGGER.error("클래스 내 handleException 호출, {}, {}", request.getRequestURI(),
e.getMessage());
Map<String, String> map = new HashMap<>();
map.put("error type", httpStatus.getReasonPhrase());
map.put("code", "400");
map.put("message", e.getMessage());
return new ResponseEntity<>(map, responseHeaders, httpStatus);
}
@GetMapping("/custom")
public void getCustomException() throws CustomException {
throw new CustomException(ExceptionClass.PRODUCT, HttpStatus.BAD_REQUEST, "getCustomException 메소드 호출");
}
}
커스텀 예외
커스텀 예외 클래스 생성에 필요한 내용
에러 타입(error type) : HttpStatus의 reasonPharse
에러 코드(error code) : HttpStatus의 value
메세지 (message) : 상황별 상세 메세지
public class Exception Throwable {
static final long serialVersionUID = -3387516993124229948L;
public Exception() {
super();
}
public Exception(String message) {
super(message);
}
public Exception(String message, Throwable cause) {
super(message, cause);
}
public Exception(Throwable) {
super(cause);
}
protected Exception(String message, Throwable cause,
boolean enableSuppression,
boolean writableStackTrace) {
super(message, cause, enableSuppression, writableStackTrace);
}
}
package com.springboot.valid_exception.common.exception;
import com.springboot.valid_exception.common.Constants;
import org.springframework.http.HttpStatus;
public class CustomException extends Exception{
private static final long serialVersionUID = 4300333310379239987L;
private Constants.ExceptionClass exceptionClass;
private HttpStatus httpStatus;
public CustomException(Constants.ExceptionClass exceptionClass, HttpStatus httpStatus,
String message) {
super(exceptionClass.toString() + message);
this.exceptionClass = exceptionClass;
this.httpStatus = httpStatus;
}
public Constants.ExceptionClass getExceptionClass() {
return exceptionClass;
}
public int getHttpStatusCode() {
return httpStatus.value();
}
public String getHttpStatusType() {
return httpStatus.getReasonPhrase();
}
public HttpStatus getHttpStatus() {
return httpStatus;
}
}
package com.springboot.valid_exception.common.exception;
import java.util.HashMap;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
@RestControllerAdvice //(basePackages = "com.springboot.valid_exception")
public class CustomExceptionHandler {
private final Logger LOGGER = LoggerFactory.getLogger(CustomExceptionHandler.class);
@ExceptionHandler(value = RuntimeException.class)
public ResponseEntity<Map<String, String>> handleException(RuntimeException e,
HttpServletRequest request) {
HttpHeaders responseHeaders = new HttpHeaders();
HttpStatus httpStatus = HttpStatus.BAD_REQUEST;
LOGGER.error("Advice 내 exceptionHandler 호출, {}, {}", request.getRequestURI(),
e.getMessage());
Map<String, String> map = new HashMap<>();
map.put("error type", httpStatus.getReasonPhrase());
map.put("code", "400");
map.put("message", e.getMessage());
return new ResponseEntity<>(map, responseHeaders, httpStatus);
}
@ExceptionHandler(value = MethodArgumentNotValidException.class)
public ResponseEntity<Map<String, String>> handleException(MethodArgumentNotValidException e,
HttpServletRequest request) {
HttpHeaders responseHeaders = new HttpHeaders();
HttpStatus httpStatus = HttpStatus.BAD_REQUEST;
Map<String, String> map = new HashMap<>();
map.put("error type", httpStatus.getReasonPhrase());
map.put("code", "400");
map.put("message", e.getMessage());
return new ResponseEntity<>(map, responseHeaders, httpStatus);
}
@ExceptionHandler(value = CustomException.class)
public ResponseEntity<Map<String, String>> handleException(CustomException e,
HttpServletRequest request) {
HttpHeaders responseHeaders = new HttpHeaders();
LOGGER.error("Advice 내 handleException 호출, {}, {}", request.getRequestURI(),
e.getMessage());
Map<String, String> map = new HashMap<>();
map.put("error type", e.getHttpStatusType());
map.put("code", Integer.toString(e.getHttpStatusCode()));
map.put("message", e.getMessage());
return new ResponseEntity<>(map, responseHeaders, e.getHttpStatus());
}
}
// 상품정보 엔티티
package com.springboot.relationship.data.entity;
import lombok.*;
import javax.persistence.*;
@Entity
@Table(name = "product_detail")
@Getter
@Setter
@NoArgsConstructor
@ToString(callSuper = true)
@EqualsAndHashCode(callSuper = true)
public class ProductDetail extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String description;
/*
@OneToOne 어노테이션에 'optional=false' 속성 설정 시 product가 null인 값을 허용하지 않음
*/
@OneToOne //(optional=false)
@JoinColumn(name = "product_number")
private Product product;
}
@JoinColumn : 어노테이션을 사용해 매핑할 외래키 설정
name : 매핑할 외래키의 이름을 설정
referencedColumnName : 외래키가 참조할 상대 테이블의 칼럼명을 지정
foreignKey : 외래키를 생성하면서 지정할 제약조건을 설정(unique, nullable, updatable 등)
// 상품정보 엔티티 객체들을 사용하기 위해 리포지토리 인터페이스 생성
package com.springboot.relationship.data.repository;
import com.springboot.relationship.data.entity.Product;
import org.springframework.data.jpa.repository.JpaRepository;
public interface ProductRepository extends JpaRepository<Product, Long> {
}
// ProductRepository와 ProductDetailRepository에 대한 테스트 코드
package com.springboot.relationship.data.repository;
import com.springboot.relationship.data.entity.Product;
import com.springboot.relationship.data.entity.ProductDetail;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class ProductDetailRepositoryTest {
@Autowired
ProductDetailRepository productDetailRepository;
@Autowired
ProductRepository productRepository;
@Test
public void saveAndReadTest1() {
Product product = new Product();
product.setName("스프링 부트 JPA");
product.setPrice(5000);
product.setStock(500);
productRepository.save(product);
ProductDetail productDetail = new ProductDetail();
productDetail.setProduct(product);
productDetail.setDescription("스프링 부트와 JPA를 함께 볼 수 있는 책");
productDetailRepository.save(productDetail);
// 생성한 데이터 조회
System.out.println("savedProduct : " + productDetailRepository.findById(
productDetail.getId()).get().getProduct());
System.out.println("savedProductDetail : " + productDetailRepository.findById(
productDetail.getId()).get());
}
}
// And, Or 키워드를 사용한 쿼리 메서드
Product findByNumberAndName(Long number, String name);
Product findByNumberOrName(Long number, String name);
(Is)Greater Than, (Is)LessThan, (Is)Between : 숫자나 datetime 칼럼을 대상으로 한 비교 연산에 사용할 수 있는 조건자 키워드. Greater Than, LessThan, 키워드는 비교 대상에 대한 초과/ 미만의 개념으로 비교 연산을 수행, 경곗값을 포함하려면 Equal 키워드를 추가하면 된다.
// GreaterThan LessThan, Between 키워드를 사용한 쿼리 메서드
List<Product> findByPriceIsGreaterThan(Long price);
List<Product> findByPriceGreaterThan(Long price);
List<Product> findByPriceGreaterThanEqual(Long price);
List<Product> findByPriceIsLessThan(Long price);
List<Product> findBypriceLessThan(Long price);
List<Product> findBypriceLessThanEqual(Long price);
List<Product> findByPriceIsBetween(Long lowPrice, Long highPrice);
List<Product> findByPriceBetween(Long lowPrice, Long highPrice);
Is)StartingWith(==StartsWith), (Is)EndingWith(==EndsWith), (Is)Containing(==Contains), (Is)Like : 컬럼 값에서 일부 일치 여부를 확인하는 조건자 키워드. SQL 쿼리문에서 값의 일부를 포함하는 값을 추출할 떄 사용하는 ‘%’ 키워드와 동일한 역할을 하는 키워드. 자동으로 생성되는 SQL문을 보면 Containing 키워드는 문자열의 양 끝, StartingWith 키워드는 문자열의 앞, EndingWith 키워드는 문자열의 끝에 ‘%’가 배치
QuerydslRepositorySupport 클래스 역시 QueryDSL라이브러리를 사용하는데 유용한 기능을 제공
가장 보편적으로 사용하는 방식은 customRepository를 활용해 리포지토리를 구현하는 방식
JpaRepository와 QuerydslRepositorySupport는 Spring Data JPA에서 제공하는 인터페이스와 클래스, 나머지 ProductRepository와 ProductRepositoryCustom, ProductRepositoryCustomImpl은 직접 구현해야 한다.
JpaRepository를 상속받는 ProductRepository를 생성
이때 직접 구현한 쿼리를 생성하기 위해서는 JpaRepository를 상속받지 않는 리포지토리 인터페이스인 ProductRepositoryCustom을 생성. 이 인터페이스에 정의하고자 하는 기능들을 메서드로 정의
ProductRepositoryCustom에서 정의한 메서드를 사용하기 위해 ProductRepository에서 ProductRepositoryCustom을 상속받습니다.
ProductRepositoryCustom에서 정의된 메서드를 기반으로 실제 쿼리를 작성하기 위해 구현체인 ProductRepositoryCustomImpl 클래스를 생성
ProductRepositoryCustomImpl 클래스에서는 다양한 방법으로 쿼리를 구현할 수 있지만 QueryDSL을 사용하기 위해 QueryDslRepositorySupport를 상속받는다.
package com.springboot.advanced_jpa.data.repository.support;
import com.springboot.advanced_jpa.data.entity.Product;
import java.util.List;
/**
* 필요한 쿼리를 작성할 메소드를 정의하는 인터페이스
*/
public interface ProductRepositoryCustom {
List<Product> findByName(String name);
}
4. 계속 Next를 진행하다가 마리아 DB의 root 패스워드 및 기본 인코딩 설정이 나오면 패스워드 입력 후 진행
5. 다음 서버 이름과 포트 번호를 입력하은 창이 나오면 원하는 포트와 이름을 적고 Next 진행 기본 포트는 3306
ORM
Object Relational Mapping, 객체 관계 매핑
자바와 같은 객체지향 언어에서 의미하는 객체(클래스)와 RDB(Relational DB)의 테이블을 자동으로 매핑하는 방법
클래스는 DB 테이블과 매핑하기 위해 만들어진 것이 아니기 때문에 RDB 테이블과 어쩔 수 없는 불일치가 존재
ORM은 이 둘(클래스, 테이블)의 불일치와 제약사항을 해결하는 역할
ORM을 이용하면 쿼리문 작성이 아닌 코드(메서드)로 데이터를 조작 가능
ORM의 장점
ORM을 사용하면서 데이터베이스 쿼리를 객체지향적으로 조작 가능
쿼리문을 작성하는 양이 현저히 줄어 개발 비용이 줄어든다.
객체지향적으로 데이터베이스에 접근할 수 있어 코드의 가독성을 높인다.
재사용 및 유지보수가 편리
ORM을 통해 매핑된 객체는 모두 독립적으로 작성되어 있어 재사용이 용이
객체들은 각 클래스로 나뉘어 있어 유지보수가 수월
데이터베이스에 대한 종속성이 줄어든다.
ORM을 통해 자동 생성된 SQL문은 객체를 기반으로 데이터베이스 테이블을 관리하기 때문에 데이터베이스에 종속적이지 않다.
데이터베이스를 교체하는 상황에서도 비교적 적은 리스크를 부담
ORM의 단점
ORM만으로 온전한 서비스를 구현하기에 한계가 있다.
복잡한 서비스의 경우 직접 쿼리를 구현하지 않고 코드로 구현하기 어렵다.
복잡한 쿼리를 정확한 설계 없이 ORM만으로 구성하게 되면 속도 저하 등의 성능 문제가 발생할 수 있다.
애플리케이션의 객체 관점과 데이터베이스의 관계 관점의 불일치가 발생
세분성(Granularity) : ORM의 자동 설계 방법에 따라 데이터베이스에 있는 테이블 수와 애플리케이션의 엔티티(Entity)클래스의 수가 다른 경우가 생긴다.(클래스가 테이블의 수보다 많아질 수 있다.)
상속성(Inheritance) : RDBMS에는 상속 개념이 없다.
식별성(Identity) : RDBMS는 기본키(primary key)로 동일성을 정의. 하지만 자바는 두 객체의 값이 같아도 다르다고 판단할 수 있다.
연관성(Associations) : 객체지향 언어는 객체를 참조함으로써 연관성을 나타내지만 RDBMS에서는 외래키를 삽입함으로써 연관성을 표현, 또한 객체지향 언어에서는 객체를 참조할 때 방향성이 존재하지만 RDBMS에는 외래키를 삽입하는 것은 양방향의 관계를 가지기 때문에 방향성이 없다.
탐색(Navigation) : 자바와 RDBMS는 어떤 값(객체)에 접근하는 방식이 다르다. 자바는 특정 값에 접근하기 위해 객체 참조 같은 연결 수단 활용, 반면 RDBMS에는 쿼리를 최소화하고 조인을 통해 여러 테이블을 로드하고 값을 추출하는 접근 방식을 택하고 있다.
JPA
Java Persistence API, 자바 진영의 ORM 기술 표준으로 채택된 인터페이스의 모음
ORM이 큰 개념이라면 JPA는 더 구체화된 스펙을 포함
JPA는 실제로 동작하는 것이 아니고 어떻게 동작해야 하는지 메커니즘을 정리한 표준 명세
JPA의 메커니즘을 보면 내부적으로 JDBC를 사용
개발자가 직접 JDBC를 구현하면 SQL에 의존하게 되는 문제 등이 있어 개발 효율이 떨어짐
JPA는 이 같은 문제점을 보완, 개발자 대신 적절한 SQL을 생성하고 DB를 조작해서 객체를 자동 매핑하는 역할 수행
JPA 기반의 구현체로는 대표적으로 세 가지가 있다.
하이버네이트
자바의 ORM 프레임워크, JPA가 정의하는 인터페이스를 구현하고 있는 JPA 구현체 중 하나
Spring Data JPA
JPA를 편리하게 사용할 수 있도록 지원하는 스프링 하위 프로젝트 중 하나
CRUD 처리에 필요한 인터페이스 제공
하이버네이트의 엔티티 매니저를 직접 다루지 않고 리포지토리를 정의해 사용함으로써 스프링이 적합한 쿼리를 동적으로 생성하는 방식으로 데이터베이스를 조작
하이버네이트에서 자주 사용되는 기능을 더 쉽게 구현한 라이브러리
영속성 컨텍스트(Persistence Context)
애플리케이션과 데이터베이스 사이에서 엔티티와 레코드의 괴리를 해소하는 기능과 객체를 보관하는 기능을 수행
엔티티 객체가 영속성 컨텍스트에 들어오면 JPA는 엔티티 객체의 매핑 정보를 데이터베이스에 반영하는 작업 수행
엔티티 객체가 영속성 컨텍스트에 들어와 JPA 관리 대상이 되는 시점부터는 해당 객체를 영속 객체라고 부른다.
영속성 컨텍스트는 세션 단위의 생명주기를 가진다. 데이터베이스에 접근하기 위한 세션이 생성되면 영속성 컨텍스트가 만들어지고, 세션이 종료되면 영속성 컨텍스트도 없어진다.
엔티티 매니저(EntityManager)
엔티티를 관리하는 객체
데이터베이스에 접근해서 CRUD 작업을 수행
Spring Data JPA를 사용하면 리포지토리를 사용해서 데이터 베이스에 접근하는데, 실제 내부 구현체인 SimpleJpaRepository가 엔티티 매니저를 사용
엔티티 매니저는 엔티티 매니저 팩토리(EntityManagerFactory)가 만든다.
엔티티 매니저 팩토리는 데이터베이스에 대응하는 객체로서 스프링 부트에서는 자동 설정 기능이 있기 때문에 application.properties에 작성한 최소한의 설정만으로 동작하지만 JPA의 구현체 중 하나의 하이버네이트에서는 persistence.xml이라는 설정 파일을 구성하고 사용해야 하는 객체이다.
URI와 URL 차이 URL은 우리가 흔히 말하는 웹 주소를 의미하며, 리소스가 어디에 있는지 알려주기 위한 경로를 의미,
반면 URI는 특성 리소스를 식별할 수 있는 식별자를 의미 웹에서는 URL을 통해 리소스가 어느 서버에 위치해 있는지 알 수 있으며, 그 서버에 접근해서 리소스에 접근하기 위해서는 대부분 URI가 필요
DTO 객체를 활용한 GET 메서드 구현
DTO?
Data Transfer Object, 다른 레이어 간의 데이터 교환에 활용, 각 클래스 및 인터페이스를 호출하면서 전달하는 매개변수로 사용되는 데이터 객체
DTO는 데이터를 교환하는 용도로만 사용되는 객체이기 때문에 DTD에는 별도의 로직이 포함되지 않음
// DTO 클래스의 예시
public class MemberDto {
private String name;;
private String email;
private String organization
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getOrganization() {
return organization;
}
}
POST API
웹 에플리케이션을 통해 데이터베이스 등의 저장소에 리소스를 저장할 때 사용되는 API
GET API에서는 URL의 경로나 파라미터에 변수를 넣어 요청을 보냄
POST API에서는 저장하고자 하는 리소스나 값을 HTTP 바디(body)에 담아 서버에 전달
그래서 URI가 GET API에 비해 간단
@RequestMapping으로 구현하기
@RequestMapping(value = "/domain", method = RequestMethod.POST)
public String postExample() {
return "Hello Post API";
}
// 위와 결과는 같다 RequestMapping보다는 PostMapping 사용!!!
@PostMapping("/domain)
public String postExample2() {
return "Hello Post API";
}
RequestBody를 활용한 Post 메서드 구현
POST 요청에서는 리소스를 담기 위해 HTTP Body에 값을 넣어 전송
Body영역에 작성되는 값은 일정한 형태를 취한다.
일반적으로 JSON 형식으로 전송
// http://localhost:8080/api/v1/post-api/member
// @RequestBody와 Map을 활용한 POST API 구현
@PostMapping("/member)
public String PostMember(@RequestBody Map<String, Object> postData) {
StringBuilder sb = new StringBuilder();
postData.entrySet().forEach(map -> {
sb.append(map.getKey() + " : " + map.getValue() + "\n");
});
return sb.toString();
}
// DTO 객체를 활용한 POST API 구현
// http://localhost:8080/api/v1/post-api/member2
@PostMapping("/member2)
public String postMemberDto(@RequestBody MemberDto memberDto) {
return memberDto.toString();
}
JSON이란? JavaScript Object Notation의 줄임말로 자바스크립트의 객체 문법을 따르는 문자 기반의 데이터 포맷 - 현재는 다수의 프로그래밍 환경에서 사용 - 대체로 네트워크를 통해 데이터를 전달할 때 사용 - 문자열 형태로 작성되기 때문에 파싱하기도 쉽다.
PUT API
웹 애플리케이션 서버를 통해 데이터베이스 같은 저장소에 존재하는 리소스 값을 업데이트 하는데 사용
POST와 비교하면 요청을 받아 실제 데이터베이스에 반영하는 과정에서 차이가 있다
컨트롤러 클래스 구현하는 방법은 POST와 거의 동일, 리소스를 서버에 전달하기 위해 HTTP Body를 활용해야 하기 때문
명세 : 해당 API가 어떤 로직을 수행하는지 설명하고 이 로직을 수행하기 위해 어떤 값을 요청하며, 이에 따른 응답값으로는 무엇을 받을 수 있는지를 정리한 자료
Swagger 의존성 추가
swagger 의존성 추가
Swagger 설정 코드
@Configuration
@EnableSwagger2
public class SwaggerConfiguration {
@Bean
public Docket api() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("com.springboot.api"))
.paths(PathSelectors.any())
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("Spring Boot Open API Test with Swagger")
.description("설명 부분")
.version("1.0.0")
.build();
}
}
// 기존 코드에 Swagger 명세를 추가
@ApiOperation(value = "GET 메서드 예제", notes = "@RequestParam을 활용한 GET Method")
@GetMapping("/request1")
public String getRequestParam(
@ApiParam(value = "이름", required = true) @RequestParam String name,
@ApiParam(value = "이메일", required = true)@RequestParam String email) {
return name + " " + email // kim test@naver.com;
}
@ApiOperation : 대상 API의 설명을 작성하기 위한 어노테이션
@ApiParam : 매개변수에 대한 설명 및 설정을 위한 어노테이션, 메서드의 매개변수 뿐 아니라 DTO 객체를 매개변수로 사용할 경우 DTO 클래스 내의 매개변수에도 정의할 수 있음
로깅 라이브러리
로깅? 애플리케이션이 동작하는 동안 시스템의 상태나 동작 정보를 시간순으로 기록하는 것을 의미 로깅은 개발 영역 중 ‘비기능 요구사항’, 즉 사용자가나 고객에게 필요한 기능은 아니다 하지만 디버깅하거나 개발 이후 발생한 문제를 해결할 때 원인을 분석하는데 꼭 필요한 요소
Logback
자바 진영에서 가장 많이 사용되는 로깅 프레임워크는 LogBack
log4j 이후에 출시된 로깅 프레임워크, slf4j를 기반으로 구현
과거에 사용되던 log4j에 비해 월등한 성능을 자랑
Logback의 특징
크게 5개의 로그 레벨(TRACE, DEBUG, INFO, WARN, ERROR)를 설정할 수 있다.
ERROR : 로직 수행 중에 시스템에 심각한 문제가 발생해서 애플리케이션의 작동이 불가능한 경우
WARN : 시스템 에러의 원인이 될 수 있는 경고 레벨을 의미
INFO : 애플리케이션의 상태 변경과 같은 정보 전달을 위해 사용
DEBUG : 애플리케이션의 디버깅을 위한 메세지를 표시하는 레벨을 의미
TRACE : DEBUG 레벨보다더 상세한 메세지를 표현하기 위한 레벨을 의미
실제 운영 환경과 개발 환경에서 각각 다른 출력 레벨을 설정해서 로그를 확인 가능
Logback의 설정 파일을 일정시간마다 스캔해서 애플리케이션을 재가동하지 않아도 설정을 변경 가능